Sub-agents, Memory Optimization, ScratchPad, Isolation Context
Read this story for free: link
Context engineering means creating the right setup for an AI before giving it a task. This setup includes:
- Instructions on how the AI should act, like being a helpful budget travel guide
- Access to useful info from databases, documents, or live sources.
- Remembering past conversations to avoid repeats or forgetting.
- Tools the AI can use, such as calculators or search features.
- Important details about you, like your preferences or location.
AI engineers are now shifting from prompt engineering to context engineering because …
context engineering focuses on providing AI with the right background and tools, making its answers smarter and more useful.
In this blog, we will explore how LangChain and LangGraph two powerful tools for building AI agents, RAG apps, and LLM apps can be used to implement contextual engineering effectively to improve our AI Agents.
All the code is available in this GitHub Repo:
Table of Contents
- What is Context Engineering?
- Scratchpad with LangGraph
- Creating StateGraph
- Memory Writing in LangGraph
- Scratchpad Selection Approach
- Memory Selection Ability
- Advantage of LangGraph BigTool Calling
- RAG with Contextual Engineering
- Compression Strategy with knowledgeable Agents
- Isolating Context using Sub-Agents Architecture
- Isolation using Sandboxed Environments
- State Isolation in LangGraph
- Summarizing Everything
What is Context Engineering?
LLMs work like a new type of operating system. The LLM acts like the CPU, and its context window works like RAM, serving as its short-term memory. But, like RAM, the context window has limited space for different information.
Just as an operating system decides what goes into RAM, “context engineering” is about choosing what the LLM should keep in its context.
Zoom image will be displayed
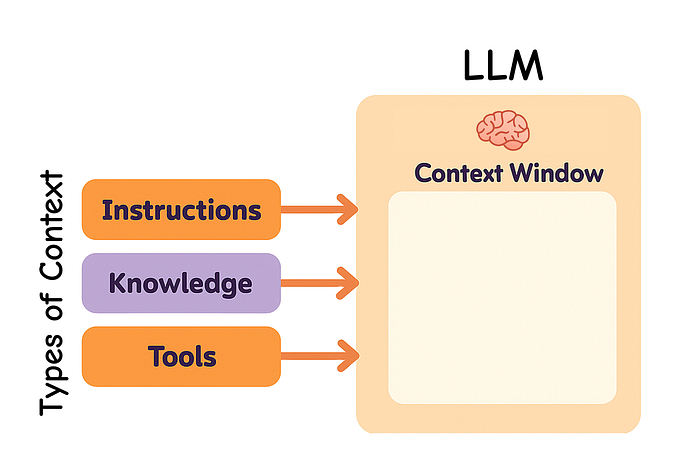
Different Context Types (Created by )
When building LLM applications, we need to manage different types of context. Context engineering covers these main types:
- Instructions: prompts, examples, memories, and tool descriptions
- Knowledge: facts, stored information, and memories
- Tools: feedback and results from tool calls
This year, more people are interested in agents because LLMs are better at thinking and using tools. Agents work on long tasks by using LLMs and tools together, choosing the next step based on the tool’s feedback.
Anthropic in their research stressed the need for it:
Agents often have conversations with hundreds of turns, so managing context carefully is crucial.
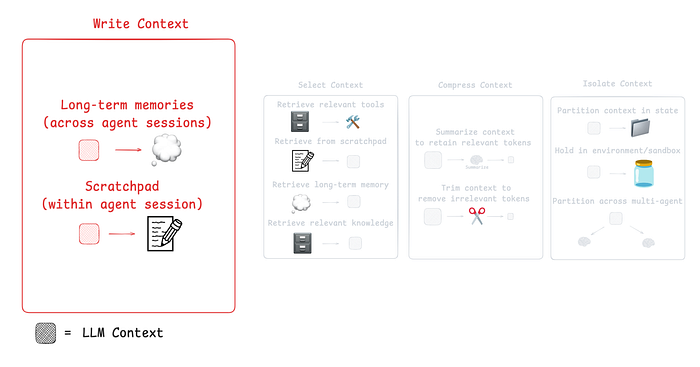
So, how are people solving this problem today? Common strategies for agent context engineering can be grouped into four main types:
- Write: creating clear and useful context
- Select: picking only the most relevant information
- Compress: shortening context to save space
- Isolate: keeping different types of context separate
LangGraph is built to support all these strategies. We will go through each of these components one by one in LangGraph and see how they help make our AI agents work better.
Scratchpad with LangGraph
Just like humans take notes to remember things for later tasks, agents can do the same using a scratchpad. It stores information outside the context window so the agent can access it whenever needed.
Zoom image will be displayed
First Component of CE (From LangChain docs)
A good example is Anthropic multi-agent researcher:
The LeadResearcher plans its approach and saves it to memory, because if the context window goes beyond 200,000 tokens, it gets cut off so saving the plan ensures it isn’t lost.
Scratchpads can be implemented in different ways:
- As a tool call that writes to a file.
- As a field in a runtime state object that persists during the session.
In short, scratchpads help agents keep important notes during a session to complete tasks effectively.
In terms of LangGraph, it supports both short-term (thread-scoped) and long-term memory.
- Short-term memory uses checkpointing to save the agent state during a session. It works like a scratchpad, letting you store information while the agent runs and retrieve it later.
The state object is the main structure passed between graph nodes. You can define its format (usually a Python dictionary). It acts as a shared scratchpad, where each node can read and update specific fields.
We will only import the modules when we need them, so we can learn step by step in a clear way.
For better and cleaner output, we will use Python pprint module for pretty printing and the Console module from the rich library. Let’s import and initialize them first:
<span id="9d66" data-selectable-paragraph=""><br><span>from</span> typing <span>import</span> TypedDict <br><br><span>from</span> rich.console <span>import</span> Console <br><span>from</span> rich.pretty <span>import</span> pprint <br><br><br>console = Console()</span>
Next, we will create a TypedDict for the state object.
<span id="d8fc" data-selectable-paragraph=""><br><br><br><span>class</span> <span>State</span>(<span>TypedDict</span>):<br> <span>"""<br> Defines the structure of the state for our joke generator workflow.<br><br> Attributes:<br> topic: The input topic for which a joke will be generated.<br> joke: The output field where the generated joke will be stored.<br> """</span><br><br> topic: <span>str</span><br> joke: <span>str</span></span>
This state object will store the topic and the joke that we ask our agent to generate based on the given topic.
Creating StateGraph
Once we define a state object, we can write context to it using a StateGraph.
A StateGraph is LangGraph’s main tool for building stateful agents or workflows. Think of it as a directed graph:
- Nodes are steps in the workflow. Each node takes the current state as input, updates it, and returns the changes.
- Edges connect nodes, defining how execution flows this can be linear, conditional, or even cyclical.
Next, we will:
- Create a chat model by choosing from Anthropic models.
- Use it in a LangGraph workflow.
<span id="ab29" data-selectable-paragraph=""><br><span>import</span> getpass<br><span>import</span> os<br><br><span>from</span> IPython.display <span>import</span> Image, display<br><span>from</span> langchain.chat_models <span>import</span> init_chat_model<br><span>from</span> langgraph.graph <span>import</span> END, START, StateGraph<br><br><br><br><span>from</span> dotenv <span>import</span> load_dotenv<br>api_key = os.getenv(<span>"ANTHROPIC_API_KEY"</span>)<br><span>if</span> <span>not</span> api_key:<br> <span>raise</span> ValueError(<span>"Missing ANTHROPIC_API_KEY in environment"</span>)<br><br><br><br>llm = init_chat_model(<span>"anthropic:claude-sonnet-4-20250514"</span>, temperature=<span>0</span>)</span>
We’ve initialized our Sonnet model. LangChain supports many open-source and closed models through their APIs, so you can use any of them.
Now, we need to create a function that generates a response using this Sonnet model.
<span id="d4d1" data-selectable-paragraph=""><br><span>def</span> <span>generate_joke</span>(<span>state: State</span>) -> <span>dict</span>[<span>str</span>, <span>str</span>]:<br> <span>"""<br> A node function that generates a joke based on the topic in the current state.<br><br> This function reads the 'topic' from the state, uses the LLM to generate a joke,<br> and returns a dictionary to update the 'joke' field in the state.<br><br> Args:<br> state: The current state of the graph, which must contain a 'topic'.<br><br> Returns:<br> A dictionary with the 'joke' key to update the state.<br> """</span><br> <br> topic = state[<span>"topic"</span>]<br> <span>print</span>(<span>f"Generating a joke about: <span>{topic}</span>"</span>)<br><br> <br> msg = llm.invoke(<span>f"Write a short joke about <span>{topic}</span>"</span>)<br><br> <br> <span>return</span> {<span>"joke"</span>: msg.content}</span>
This function simply returns a dictionary containing the generated response (the joke).
Now, using the StateGraph, we can easily build and compile the graph. Let’s do that next.
<span id="921d" data-selectable-paragraph=""><br><br>workflow = StateGraph(State)<br><br><br>workflow.add_node(<span>"generate_joke"</span>, generate_joke)<br><br><br><br>workflow.add_edge(START, <span>"generate_joke"</span>)<br><br>workflow.add_edge(<span>"generate_joke"</span>, END)<br><br><br>chain = workflow.<span>compile</span>()<br><br><br><br>display(Image(chain.get_graph().draw_mermaid_png()))</span>

Our Generated Graph (Created by )
Now we can execute this workflow.
<span id="0366" data-selectable-paragraph=""><br><br><br>joke_generator_state = chain.invoke({<span>"topic"</span>: <span>"cats"</span>})<br><br><br><br><br>console.<span>print</span>(<span>"\n[bold blue]Joke Generator State:[/bold blue]"</span>)<br>pprint(joke_generator_state)<br><br><br><br><br>{<br> <span>'topic'</span>: <span>'cats'</span>, <br> <span>'joke'</span>: <span>'Why did the cat join a band?\n\nBecause it wanted to be the purr-cussionist!'</span><br>}</span>
It returns the dictionary which is basically the joke generation state of our agent. This simple example shows how we can write context to state.
You can learn more about Checkpointing for saving and resuming graph states, and Human-in-the-loop for pausing workflows to get human input before continuing.
Memory Writing in LangGraph
Scratchpads help agents work within a single session, but sometimes agents need to remember things across multiple sessions.
- Reflexion introduced the idea of agents reflecting after each turn and reusing self-generated hints.
- Generative Agents created long-term memories by summarizing past agent feedback.
Zoom image will be displayed

Memory Writing (From LangChain docs)
These ideas are now used in products like ChatGPT, Cursor, and Windsurf, which automatically create long-term memories from user interactions.
- Checkpointing saves the graph’s state at each step in a thread. A thread has a unique ID and usually represents one interaction — like a single chat in ChatGPT.
- Long-term memory lets you keep specific context across threads. You can save individual files (e.g., a user profile) or collections of memories.
- It uses the BaseStore interface, a key-value store. You can use it in memory (as shown here) or with LangGraph Platform deployments.
Let’s now create an InMemoryStore to use across multiple sessions in this notebook.
<span id="690c" data-selectable-paragraph=""><span>from</span> langgraph.store.memory <span>import</span> InMemoryStore<br><br><br><br><br>store = InMemoryStore()<br><br><br><br><br><br>namespace = (<span>"rlm"</span>, <span>"joke_generator"</span>)<br><br><br><br><br><br>store.put(<br> namespace, <br> <span>"last_joke"</span>, <br> {<span>"joke"</span>: joke_generator_state[<span>"joke"</span>]}, <br>)</span>
We’ll discuss how to select context from a namespace in the upcoming section. For now, we can use the search method to view items within a namespace and confirm that we successfully wrote to it.
<span id="35e2" data-selectable-paragraph=""><br>stored_items = <span>list</span>(store.search(namespace))<br><br><br>console.<span>print</span>(<span>"\n[bold green]Stored Items in Memory:[/bold green]"</span>)<br>pprint(stored_items)<br><br><br><br>[<br> Item(namespace=[<span>'rlm'</span>, <span>'joke_generator'</span>], key=<span>'last_joke'</span>, <br> value={<span>'joke'</span>: <span>'Why did the cat join a band?\n\nBecause it wanted to be the purr-cussionist!'</span>},<br> created_at=<span>'2025-07-24T02:12:25.936238+00:00'</span>,<br> updated_at=<span>'2025-07-24T02:12:25.936238+00:00'</span>, score=<span>None</span>)<br>]</span>
Now, let’s embed everything we did into a LangGraph workflow.
We will compile the workflow with two arguments:
checkpointersaves the graph state at each step in a thread.storekeeps context across different threads.
<span id="7c8d" data-selectable-paragraph=""><span>from</span> langgraph.checkpoint.memory <span>import</span> InMemorySaver<br><span>from</span> langgraph.store.base <span>import</span> BaseStore<br><span>from</span> langgraph.store.memory <span>import</span> InMemoryStore<br><br><br>checkpointer = InMemorySaver() <br>memory_store = InMemoryStore() <br><br><br><span>def</span> <span>generate_joke</span>(<span>state: State, store: BaseStore</span>) -> <span>dict</span>[<span>str</span>, <span>str</span>]:<br> <span>"""Generate a joke with memory awareness.<br> <br> This enhanced version checks for existing jokes in memory<br> before generating new ones.<br> <br> Args:<br> state: Current state containing the topic<br> store: Memory store for persistent context<br> <br> Returns:<br> Dictionary with the generated joke<br> """</span><br> <br> existing_jokes = <span>list</span>(store.search(namespace))<br> <span>if</span> existing_jokes:<br> existing_joke = existing_jokes[<span>0</span>].value<br> <span>print</span>(<span>f"Existing joke: <span>{existing_joke}</span>"</span>)<br> <span>else</span>:<br> <span>print</span>(<span>"Existing joke: No existing joke"</span>)<br><br> <br> msg = llm.invoke(<span>f"Write a short joke about <span>{state[<span>'topic'</span>]}</span>"</span>)<br> <br> <br> store.put(namespace, <span>"last_joke"</span>, {<span>"joke"</span>: msg.content})<br><br> <br> <span>return</span> {<span>"joke"</span>: msg.content}<br><br><br><br>workflow = StateGraph(State)<br><br><br>workflow.add_node(<span>"generate_joke"</span>, generate_joke)<br><br><br>workflow.add_edge(START, <span>"generate_joke"</span>)<br>workflow.add_edge(<span>"generate_joke"</span>, END)<br><br><br>chain = workflow.<span>compile</span>(checkpointer=checkpointer, store=memory_store)</span>
Great! Now we can simply execute the updated workflow and test how it works with the memory feature enabled.
<span id="a2dc" data-selectable-paragraph=""><br>config = {<span>"configurable"</span>: {<span>"thread_id"</span>: <span>"1"</span>}}<br>joke_generator_state = chain.invoke({<span>"topic"</span>: <span>"cats"</span>}, config)<br><br><br>console.<span>print</span>(<span>"\n[bold cyan]Workflow Result (Thread 1):[/bold cyan]"</span>)<br>pprint(joke_generator_state)<br><br><br><br>Existing joke: No existing joke<br><br>Workflow Result (Thread <span>1</span>):<br>{ <span>'topic'</span>: <span>'cats'</span>, <br> <span>'joke'</span>: <span>'Why did the cat join a band?\n\nBecause it wanted to be the purr-cussionist!'</span>}</span>
Since this is thread 1, there’s no existing joke stored in our AI agent’s memory which is exactly what we’d expect for a fresh thread.
Because we compiled the workflow with a checkpointer, we can now view the latest state of the graph.
<span id="7f8f" data-selectable-paragraph=""><br><br><br><br>latest_state = chain.get_state(config)<br><br><br><br><br>console.<span>print</span>(<span>"\n[bold magenta]Latest Graph State (Thread 1):[/bold magenta]"</span>)<br>pprint(latest_state)</span>
Take a look at the output:
<span id="d175" data-selectable-paragraph=""><br>Latest Graph State:<br><br>StateSnapshot(<br> values={<br> <span>'topic'</span>: <span>'cats'</span>,<br> <span>'joke'</span>: <span>'Why did the cat join a band?\n\nBecause it wanted to be the purr-cussionist!'</span><br> },<br> <span>next</span>=(),<br> config={<br> <span>'configurable'</span>: {<br> <span>'thread_id'</span>: <span>'1'</span>,<br> <span>'checkpoint_ns'</span>: <span>''</span>,<br> <span>'checkpoint_id'</span>: <span>'1f06833a-53a7-65a8-8001-548e412001c4'</span><br> }<br> },<br> metadata={<span>'source'</span>: <span>'loop'</span>, <span>'step'</span>: <span>1</span>, <span>'parents'</span>: {}},<br> created_at=<span>'2025-07-24T02:12:27.317802+00:00'</span>,<br> parent_config={<br> <span>'configurable'</span>: {<br> <span>'thread_id'</span>: <span>'1'</span>,<br> <span>'checkpoint_ns'</span>: <span>''</span>,<br> <span>'checkpoint_id'</span>: <span>'1f06833a-4a50-6108-8000-245cde0c2411'</span><br> }<br> },<br> tasks=(),<br> interrupts=()<br>)</span>
You can see that our state now shows the last conversation we had with the agent in this case, where we asked it to tell a joke about cats.
Let’s rerun the workflow with different ID.
<span id="9b45" data-selectable-paragraph=""><br>config = {<span>"configurable"</span>: {<span>"thread_id"</span>: <span>"2"</span>}}<br>joke_generator_state = chain.invoke({<span>"topic"</span>: <span>"cats"</span>}, config)<br><br><br>console.<span>print</span>(<span>"\n[bold yellow]Workflow Result (Thread 2):[/bold yellow]"</span>)<br>pprint(joke_generator_state)<br><br><br><br>Existing joke: {<span>'joke'</span>: <span>'Why did the cat join a band?\n\nBecause it wanted to be the purr-cussionist!'</span>}<br>Workflow Result (Thread <span>2</span>):<br>{<span>'topic'</span>: <span>'cats'</span>, <span>'joke'</span>: <span>'Why did the cat join a band?\n\nBecause it wanted to be the purr-cussionist!'</span>}</span>
We can see that the joke from the first thread has been successfully saved to memory.
You can learn more about LangMem for memory abstractions and the Ambient Agents Course for an overview of memory in LangGraph agents.
Scratchpad Selection Approach
How you select context from a scratchpad depends on its implementation:
- If it’s a tool, the agent can read it directly by making a tool call.
- If it’s part of the agent’s runtime state, you (the developer) decide which parts of the state to share with the agent at each step. This gives you fine-grained control over what context is exposed.
Zoom image will be displayed
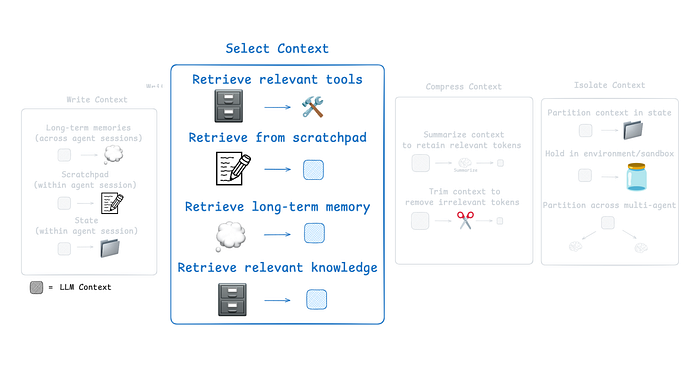
Second Component of CE (From LangChain docs)
In previous step, we learned how to write to the LangGraph state object. Now, we’ll learn how to select context from the state and pass it to an LLM call in a downstream node.
This selective approach lets you control exactly what context the LLM sees during execution.
<span id="607a" data-selectable-paragraph=""><span>def</span> <span>generate_joke</span>(<span>state: State</span>) -> <span>dict</span>[<span>str</span>, <span>str</span>]:<br> <span>"""Generate an initial joke about the topic.<br> <br> Args:<br> state: Current state containing the topic<br> <br> Returns:<br> Dictionary with the generated joke<br> """</span><br> msg = llm.invoke(<span>f"Write a short joke about <span>{state[<span>'topic'</span>]}</span>"</span>)<br> <span>return</span> {<span>"joke"</span>: msg.content}<br><br><br><span>def</span> <span>improve_joke</span>(<span>state: State</span>) -> <span>dict</span>[<span>str</span>, <span>str</span>]:<br> <span>"""Improve an existing joke by adding wordplay.<br> <br> This demonstrates selecting context from state - we read the existing<br> joke from state and use it to generate an improved version.<br> <br> Args:<br> state: Current state containing the original joke<br> <br> Returns:<br> Dictionary with the improved joke<br> """</span><br> <span>print</span>(<span>f"Initial joke: <span>{state[<span>'joke'</span>]}</span>"</span>)<br> <br> <br> msg = llm.invoke(<span>f"Make this joke funnier by adding wordplay: <span>{state[<span>'joke'</span>]}</span>"</span>)<br> <span>return</span> {<span>"improved_joke"</span>: msg.content}</span>
To make things a bit more complex, we’re now adding two workflows to our agent:
- Generate Joke same as before.
- Improve Joke takes the generated joke and makes it better.
This setup will help us understand how scratchpad selection works in LangGraph. Let’s now compile this workflow the same way we did earlier and check how our graph looks.
<span id="0039" data-selectable-paragraph=""><br>workflow = StateGraph(State)<br><br><br>workflow.add_node(<span>"generate_joke"</span>, generate_joke)<br>workflow.add_node(<span>"improve_joke"</span>, improve_joke)<br><br><br>workflow.add_edge(START, <span>"generate_joke"</span>)<br>workflow.add_edge(<span>"generate_joke"</span>, <span>"improve_joke"</span>)<br>workflow.add_edge(<span>"improve_joke"</span>, END)<br><br><br>chain = workflow.<span>compile</span>()<br><br><br>display(Image(chain.get_graph().draw_mermaid_png()))</span>
Our Generated Graph (Created by )
When we execute this workflow, this is what we get.
<span id="53f5" data-selectable-paragraph=""><br>joke_generator_state = chain.invoke({<span>"topic"</span>: <span>"cats"</span>})<br><br><br>console.<span>print</span>(<span>"\n[bold blue]Final Workflow State:[/bold blue]"</span>)<br>pprint(joke_generator_state)<br><br><br>Initial joke: Why did the cat join a band?<br><br>Because it wanted to be the purr-cussionist!<br>Final Workflow State:<br>{<br> <span>'topic'</span>: <span>'cats'</span>,<br> <span>'joke'</span>: <span>'Why did the cat join a band?\n\nBecause it wanted to be the purr-cussionist!'</span>}</span>
Now that we have executed our workflow, we can move on to using it in our memory selection step.
Memory Selection Ability
If agents can save memories, they also need to select relevant memories for the task at hand. This is useful for:
- Episodic memories few-shot examples showing desired behavior.
- Procedural memories instructions to guide behavior.
- Semantic memories facts or relationships that provide task-relevant context.
Some agents use narrow, predefined files to store memories:
- Claude Code uses
[CLAUDE.md](http://claude.md/). - Cursor and Windsurf use “rules” files for instructions or examples.
But when storing a large collection of facts (semantic memories), selection gets harder.
- ChatGPT sometimes retrieves irrelevant memories, as shown by Simon Willison when ChatGPT wrongly fetched his location and injected it into an image making the context feel like it “no longer belonged to him”.
- To improve selection, embeddings or knowledge graphs are used for indexing.
In our previous section, we wrote to the InMemoryStore in graph nodes. Now, we can select context from it using the get method to pull relevant state into our workflow.
<span id="0e8b" data-selectable-paragraph=""><span>from</span> langgraph.store.memory <span>import</span> InMemoryStore<br><br><br>store = InMemoryStore()<br><br><br>namespace = (<span>"rlm"</span>, <span>"joke_generator"</span>)<br><br><br>store.put(<br> namespace, <br> <span>"last_joke"</span>, <br> {<span>"joke"</span>: joke_generator_state[<span>"joke"</span>]} <br>)<br><br><br>retrieved_joke = store.get(namespace, <span>"last_joke"</span>).value<br><br><br>console.<span>print</span>(<span>"\n[bold green]Retrieved Context from Memory:[/bold green]"</span>)<br>pprint(retrieved_joke)<br><br><br><br>Retrieved Context <span>from</span> Memory:<br>{<span>'joke'</span>: <span>'Why did the cat join a band?\n\nBecause it wanted to be the purr-cussionist!'</span>}</span>
It successfully retrieves the correct joke from memory.
Now, we need to write a proper generate_joke function that can:
- Take the current state (for the scratchpad context).
- Use memory (to fetch past jokes if we’re performing a joke improvement task).
Let’s code that next.
<span id="0c7d" data-selectable-paragraph=""><br>checkpointer = InMemorySaver()<br>memory_store = InMemoryStore()<br><br><br><span>def</span> <span>generate_joke</span>(<span>state: State, store: BaseStore</span>) -> <span>dict</span>[<span>str</span>, <span>str</span>]:<br> <span>"""Generate a joke with memory-aware context selection.<br> <br> This function demonstrates selecting context from memory before<br> generating new content, ensuring consistency and avoiding duplication.<br> <br> Args:<br> state: Current state containing the topic<br> store: Memory store for persistent context<br> <br> Returns:<br> Dictionary with the generated joke<br> """</span><br> <br> prior_joke = store.get(namespace, <span>"last_joke"</span>)<br> <span>if</span> prior_joke:<br> prior_joke_text = prior_joke.value[<span>"joke"</span>]<br> <span>print</span>(<span>f"Prior joke: <span>{prior_joke_text}</span>"</span>)<br> <span>else</span>:<br> <span>print</span>(<span>"Prior joke: None!"</span>)<br><br> <br> prompt = (<br> <span>f"Write a short joke about <span>{state[<span>'topic'</span>]}</span>, "</span><br> <span>f"but make it different from any prior joke you've written: <span>{prior_joke_text <span>if</span> prior_joke <span>else</span> <span>'None'</span>}</span>"</span><br> )<br> msg = llm.invoke(prompt)<br><br> <br> store.put(namespace, <span>"last_joke"</span>, {<span>"joke"</span>: msg.content})<br><br> <span>return</span> {<span>"joke"</span>: msg.content}</span>
We can now simply execute this memory-aware workflow the same way we did earlier.
<span id="6038" data-selectable-paragraph=""><br>workflow = StateGraph(State)<br>workflow.add_node(<span>"generate_joke"</span>, generate_joke)<br><br><br>workflow.add_edge(START, <span>"generate_joke"</span>)<br>workflow.add_edge(<span>"generate_joke"</span>, END)<br><br><br>chain = workflow.<span>compile</span>(checkpointer=checkpointer, store=memory_store)<br><br><br>config = {<span>"configurable"</span>: {<span>"thread_id"</span>: <span>"1"</span>}}<br>joke_generator_state = chain.invoke({<span>"topic"</span>: <span>"cats"</span>}, config)<br><br><br><br>Prior joke: <span>None</span>!</span>
No prior joke is detected, We can now print the latest state structure.
<span id="4aec" data-selectable-paragraph=""><br>latest_state = chain.get_state(config)<br><br>console.<span>print</span>(<span>"\n[bold magenta]Latest Graph State:[/bold magenta]"</span>)<br>pprint(latest_state)</span>
Our output:
<span id="228c" data-selectable-paragraph=""><br>StateSnapshot(<br> values={<br> <span>'topic'</span>: <span>'cats'</span>,<br> <span>'joke'</span>: <span>"Here's a new one:\n\nWhy did the cat join a band?\n\nBecause it wanted to be the purr-cussionist!"</span><br> },<br> <span>next</span>=(),<br> config={<br> <span>'configurable'</span>: {<br> <span>'thread_id'</span>: <span>'1'</span>,<br> <span>'checkpoint_ns'</span>: <span>''</span>,<br> <span>'checkpoint_id'</span>: <span>'1f068357-cc8d-68cb-8001-31f64daf7bb6'</span><br> }<br> },<br> metadata={<span>'source'</span>: <span>'loop'</span>, <span>'step'</span>: <span>1</span>, <span>'parents'</span>: {}},<br> created_at=<span>'2025-07-24T02:25:38.457825+00:00'</span>,<br> parent_config={<br> <span>'configurable'</span>: {<br> <span>'thread_id'</span>: <span>'1'</span>,<br> <span>'checkpoint_ns'</span>: <span>''</span>,<br> <span>'checkpoint_id'</span>: <span>'1f068357-c459-6deb-8000-16ce383a5b6b'</span><br> }<br> },<br> tasks=(),<br> interrupts=()<br>)</span>
We fetch the previous joke from memory and pass it to the LLM to improve it.
<span id="1895" data-selectable-paragraph=""><br>config = {<span>"configurable"</span>: {<span>"thread_id"</span>: <span>"2"</span>}}<br>joke_generator_state = chain.invoke({<span>"topic"</span>: <span>"cats"</span>}, config)<br><br><br><br>Prior joke: Here <span>is</span> a new one:<br>Why did the cat join a band?<br>Because it wanted to be the purr-cussionist!</span>
It has successfully fetched the correct joke from memory and improved it as expected.
Advantage of LangGraph BigTool Calling
Agents use tools, but giving them too many tools can cause confusion, especially when tool descriptions overlap. This makes it harder for the model to choose the right tool.
A solution is to use RAG (Retrieval-Augmented Generation) on tool descriptions to fetch only the most relevant tools based on semantic similarity a method Drew Breunig calls tool loadout.
According to recent research, this improves tool selection accuracy by up to 3x.
For tool selection, the LangGraph Bigtool library is ideal. It applies semantic similarity search over tool descriptions to select the most relevant ones for the task. It uses LangGraph’s long-term memory store, allowing agents to search and retrieve the right tools for a given problem.
Let’s understandlanggraph-bigtool by using an agent with all functions from Python’s built-in math library.
<span id="d3a9" data-selectable-paragraph=""><span>import</span> math<br><br><br>all_tools = []<br><span>for</span> function_name <span>in</span> <span>dir</span>(math):<br> function = <span>getattr</span>(math, function_name)<br> <span>if</span> <span>not</span> <span>isinstance</span>(<br> function, types.BuiltinFunctionType<br> ):<br> <span>continue</span><br> <br> <span>if</span> tool := convert_positional_only_function_to_tool(<br> function<br> ):<br> all_tools.append(tool)</span>
We first append all functions from Python’s math module into a list. Next, we need to convert these tool descriptions into vector embeddings so the agent can perform semantic similarity searches.
For this, we will use an embedding model in our case, the OpenAI text-embedding model.
<span id="5709" data-selectable-paragraph=""><br><br>tool_registry = {<br> <span>str</span>(uuid.uuid4()): tool<br> <span>for</span> tool <span>in</span> all_tools<br>}<br><br><br><br>embeddings = init_embeddings(<span>"openai:text-embedding-3-small"</span>)<br><br>store = InMemoryStore(<br> index={<br> <span>"embed"</span>: embeddings,<br> <span>"dims"</span>: <span>1536</span>,<br> <span>"fields"</span>: [<span>"description"</span>],<br> }<br>)<br><span>for</span> tool_id, tool <span>in</span> tool_registry.items():<br> store.put(<br> (<span>"tools"</span>,),<br> tool_id,<br> {<br> <span>"description"</span>: <span>f"<span>{tool.name}</span>: <span>{tool.description}</span>"</span>,<br> },<br> )</span>
Each function is assigned a unique ID, and we structure these functions into a proper standardized format. This structured format ensures that the functions can be easily converted into embeddings for semantic search.
Let’s now visualize the agent to see how it looks with all the math functions embedded and ready for semantic search!
<span id="c358" data-selectable-paragraph=""><br>builder = create_agent(llm, tool_registry)<br>agent = builder.<span>compile</span>(store=store)<br>agent</span>
Zoom image will be displayed
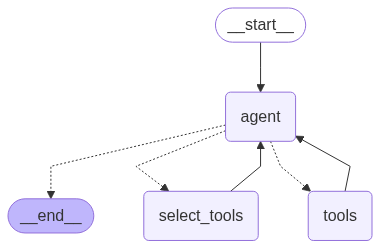
Our Tool Agent (Created by )
We can now invoke our agent with a simple query and observe how our tool-calling agent selects and uses the most relevant math functions to answer the question.
<span id="7fad" data-selectable-paragraph=""><br><span>from</span> utils <span>import</span> format_messages<br><br><br><br>query = <span>"Use available tools to calculate arc cosine of 0.5."</span><br><br><br><br>result = agent.invoke({<span>"messages"</span>: query})<br><br><br>format_messages(result[<span>'messages'</span>])</span>
<span id="fcfe" data-selectable-paragraph="">┌────────────── Human ───────────────┐<br>│ Use available tools to calculate │<br>│ arc cosine of 0.5. │<br>└──────────────────────────────────────┘<br><br>┌────────────── 📝 AI ─────────────────┐<br>│ I will search for a tool to calculate│<br>│ the arc cosine of 0.5. │<br>│ │<br>│ 🔧 Tool Call: retrieve_tools │<br>│ Args: { │<br>│ "query": "arc cosine arccos │<br>│ inverse cosine trig" │<br>│ } │<br>└──────────────────────────────────────┘<br><br>┌────────────── 🔧 Tool Output ────────┐<br>│ Available tools: ['acos', 'acosh'] │<br>└──────────────────────────────────────┘<br><br>┌────────────── 📝 AI ─────────────────┐<br>│ Perfect! I found the `acos` function │<br>│ which calculates the arc cosine. │<br>│ Now I will use it to calculate the │<br>│ arc │<br>│ cosine of 0.5. │<br>│ │<br>│ 🔧 Tool Call: acos │<br>│ Args: { "x": 0.5 } │<br>└──────────────────────────────────────┘<br><br>┌────────────── 🔧 Tool Output ────────┐<br>│ 1.0471975511965976 │<br>└──────────────────────────────────────┘<br><br>┌────────────── 📝 AI ─────────────────┐<br>│ The arc cosine of 0.5 is ≈**1.047** │<br>│ radians. │<br>│ │<br>│ ✔ Check: cos(π/3)=0.5, π/3≈1.047 rad │<br>│ (60°). │<br>└──────────────────────────────────────┘</span>
You can see how efficiently our ai agent is calling the correct tool. You can learn more about:
- Toolshed introduces Toolshed Knowledge Bases and Advanced RAG-Tool Fusion for better tool selection in AI agents.
- Graph RAG-Tool Fusion combines vector retrieval with graph traversal to capture tool dependencies.
- LLM-Tool-Survey a comprehensive survey of tool learning with LLMs.
- ToolRet a benchmark for evaluating and improving tool retrieval in LLMs.
RAG with Contextual Engineering
RAG (Retrieval-Augmented Generation) is a vast topic, and code agents are some of the best examples of agentic RAG in production.
In practice, RAG is often the central challenge of context engineering. As Varun from Windsurf points out:
Indexing ≠ context retrieval. Embedding search with AST-based chunking works, but fails as codebases grow. We need hybrid retrieval: grep/file search, knowledge-graph linking, and relevance-based re-ranking.
LangGraph provides tutorials and videos to help integrate RAG into agents. Typically, you build a retrieval tool that can use any combination of RAG techniques mentioned above.
To demonstrate, we’ll fetch documents for our RAG system using three of the most recent pages from Lilian Weng’s excellent blog.
We will start by pulling page content with the WebBaseLoader utility.
<span id="0f90" data-selectable-paragraph=""><br><span>from</span> langchain_community.document_loaders <span>import</span> WebBaseLoader<br><br><br>urls = [<br> <span>"https://lilianweng.github.io/posts/2025-05-01-thinking/"</span>,<br> <span>"https://lilianweng.github.io/posts/2024-11-28-reward-hacking/"</span>,<br> <span>"https://lilianweng.github.io/posts/2024-07-07-hallucination/"</span>,<br> <span>"https://lilianweng.github.io/posts/2024-04-12-diffusion-video/"</span>,<br>]<br><br><br><br>docs = [WebBaseLoader(url).load() <span>for</span> url <span>in</span> urls]</span>
There are different ways to chunk data for RAG, and proper chunking is crucial for effective retrieval.
Here, we’ll split the fetched documents into smaller chunks before indexing them into our vectorstore. We’ll use a simple, direct approach such as recursive chunking with overlapping segments to preserve context across chunks while keeping them manageable for embedding and retrieval.
<span id="3b2b" data-selectable-paragraph=""><br><span>from</span> langchain_text_splitters <span>import</span> RecursiveCharacterTextSplitter<br><br><br><br>docs_list = [item <span>for</span> sublist <span>in</span> docs <span>for</span> item <span>in</span> sublist]<br><br><br><br>text_splitter = RecursiveCharacterTextSplitter.from_tiktoken_encoder(<br> chunk_size=<span>2000</span>, chunk_overlap=<span>50</span><br>)<br><br><br>doc_splits = text_splitter.split_documents(docs_list)</span>
Now that we have our split documents, we can index them into a vector store that we’ll use for semantic search.
<span id="ac07" data-selectable-paragraph=""><br><span>from</span> langchain_core.vectorstores <span>import</span> InMemoryVectorStore<br><br><br><br><br>vectorstore = InMemoryVectorStore.from_documents(<br> documents=doc_splits, embedding=embeddings<br>)<br><br><br><br><br>retriever = vectorstore.as_retriever()</span>
We have to create a retriever tool that we can use in our agent.
<span id="6aee" data-selectable-paragraph=""><br><span>from</span> langchain.tools.retriever <span>import</span> create_retriever_tool<br><br><br><br><br>retriever_tool = create_retriever_tool(<br> retriever,<br> <span>"retrieve_blog_posts"</span>,<br> <span>"Search and return information about Lilian Weng blog posts."</span>,<br>)<br><br><br><br></span>
Now, we can implement an agent that can select context from the tool.
<span id="b6a0" data-selectable-paragraph=""><br>tools = [retriever_tool]<br>tools_by_name = {tool.name: tool <span>for</span> tool <span>in</span> tools}<br>llm_with_tools = llm.bind_tools(tools)</span>
For RAG based solutions, we need to create a clear system prompt to guide our agent’s behavior. This prompt acts as its core instruction set.
<span id="62c9" data-selectable-paragraph=""><span>from</span> langgraph.graph <span>import</span> MessagesState<br><span>from</span> langchain_core.messages <span>import</span> SystemMessage, ToolMessage<br><span>from</span> typing_extensions <span>import</span> <span>Literal</span><br><br>rag_prompt = <span>"""You are a helpful assistant tasked with retrieving information from a series of technical blog posts by Lilian Weng. <br>Clarify the scope of research with the user before using your retrieval tool to gather context. Reflect on any context you fetch, and<br>proceed until you have sufficient context to answer the user's research request."""</span></span>
Next, we define the nodes of our graph. We’ll need two main nodes:
llm_callThis is the brain of our agent. It takes the current conversation history (user query + previous tool outputs). It then decides the next step, call a tool or generate a final answer.tool_nodeThis is the action part of our agent. It executes the tool call requested byllm_call. It returns the tool’s result back to the agent.
<span id="d77d" data-selectable-paragraph=""><br><br><span>def</span> <span>llm_call</span>(<span>state: MessagesState</span>):<br> <span>"""LLM decides whether to call a tool or generate a final answer."""</span><br> <br> messages_with_prompt = [SystemMessage(content=rag_prompt)] + state[<span>"messages"</span>]<br> <br> <br> response = llm_with_tools.invoke(messages_with_prompt)<br> <br> <br> <span>return</span> {<span>"messages"</span>: [response]}<br> <br><span>def</span> <span>tool_node</span>(<span>state: <span>dict</span></span>):<br> <span>"""Performs the tool call and returns the observation."""</span><br> <br> last_message = state[<span>"messages"</span>][-<span>1</span>]<br> <br> <br> result = []<br> <span>for</span> tool_call <span>in</span> last_message.tool_calls:<br> tool = tools_by_name[tool_call[<span>"name"</span>]]<br> observation = tool.invoke(tool_call[<span>"args"</span>])<br> result.append(ToolMessage(content=<span>str</span>(observation), tool_call_id=tool_call[<span>"id"</span>]))<br> <br> <br> <span>return</span> {<span>"messages"</span>: result}</span>
We need a way to control the agent’s flow deciding whether it should call a tool or if it’s finished.
To handle this, we will create a conditional edge function called should_continue.
- This function checks if the last message from the LLM contains a tool call.
- If it does, the graph routes to the
tool_node. - If not, the execution ends.
<span id="cdce" data-selectable-paragraph=""><br><br><span>def</span> <span>should_continue</span>(<span>state: MessagesState</span>) -> <span>Literal</span>[<span>"Action"</span>, END]:<br> <span>"""Decides the next step based on whether the LLM made a tool call."""</span><br> last_message = state[<span>"messages"</span>][-<span>1</span>]<br> <br> <br> <span>if</span> last_message.tool_calls:<br> <span>return</span> <span>"Action"</span><br> <br> <span>return</span> END</span>
We can now simply build the workflow and compile the graph.
<span id="87cc" data-selectable-paragraph=""><br>agent_builder = StateGraph(MessagesState)<br><br><br>agent_builder.add_node(<span>"llm_call"</span>, llm_call)<br>agent_builder.add_node(<span>"environment"</span>, tool_node)<br><br><br>agent_builder.add_edge(START, <span>"llm_call"</span>)<br>agent_builder.add_conditional_edges(<br> <span>"llm_call"</span>,<br> should_continue,<br> {<br> <br> <span>"Action"</span>: <span>"environment"</span>,<br> END: END,<br> },<br>)<br>agent_builder.add_edge(<span>"environment"</span>, <span>"llm_call"</span>)<br><br><br>agent = agent_builder.<span>compile</span>()<br><br><br>display(Image(agent.get_graph(xray=<span>True</span>).draw_mermaid_png()))</span>
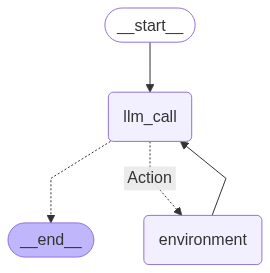
RAG Based Agent (Created by )
The graph shows a clear cycle:
- the agent starts, calls the LLM.
- based on the LLM’s decision, it either performs an action (calls our retriever tool) and loops back, or it finishes and provides the answer
Let’s test our RAG agent. We’ll ask it a specific question about “reward hacking” that can only be answered by retrieving information from the blog posts we indexed.
<span id="7ac0" data-selectable-paragraph=""><br>query = <span>"What are the types of reward hacking discussed in the blogs?"</span><br><br><br>result = agent.invoke({<span>"messages"</span>: [(<span>"user"</span>, query)]})<br><br><br><br>format_messages(result[<span>'messages'</span>])</span>
<span id="8b27" data-selectable-paragraph="">┌────────────── Human ───────────────┐<br>│ Clarify scope: I want types of │<br>│ reward hacking from Lilian Weng’s │<br>│ blog on RL. │<br>└──────────────────────────────────────┘<br><br>┌────────────── 📝 AI ─────────────────┐<br>│ Fetching context from her posts... │<br>└──────────────────────────────────────┘<br><br>┌────────────── 🔧 Tool Output ────────┐<br>│ She lists 3 main types of reward │<br>│ hacking in RL: │<br>└──────────────────────────────────────┘<br><br>┌────────────── 📝 AI ─────────────────┐<br>│ 1. **Spec gaming** – Exploit reward │<br>│ loopholes, not real goal. │<br>│ │<br>│ 2. **Reward tampering** – Change or │<br>│ hack reward signals. │<br>│ │<br>│ 3. **Wireheading** – Self-stimulate │<br>│ reward instead of task. │<br>└──────────────────────────────────────┘<br><br>┌────────────── 📝 AI ─────────────────┐<br>│ These can cause harmful, unintended │<br>│ behaviors in RL agents. │<br>└──────────────────────────────────────┘</span>
As you can see, the agent correctly identified that it needed to use its retrieval tool. It then successfully retrieved the relevant context from the blog posts and used that information to provide a detailed and accurate answer.
This is a perfect example of how contextual engineering through RAG can create powerful, knowledgeable agents.
Compression Strategy with knowledgeable Agents
Agent interactions can span hundreds of turns and involve token-heavy tool calls. Summarization is a common way to manage this.
Zoom image will be displayed
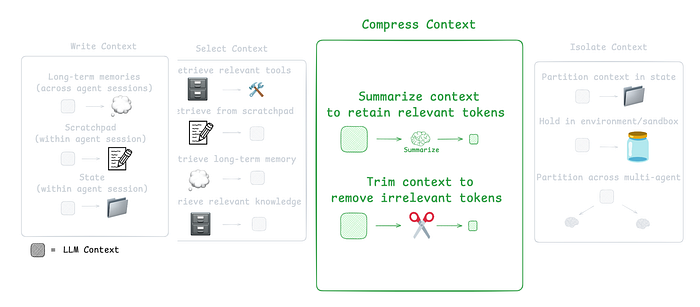
Third Component of CE (From LangChain docs)
For example:
- Claude Code uses “auto-compact” when the context window exceeds 95%, summarizing the entire user-agent interaction history.
- Summarization can compress an agent trajectory using strategies like recursive or hierarchical summarization.
You can also add summarization at specific points:
- After token-heavy tool calls (e.g., search tools) example here.
- At agent-agent boundaries for knowledge transfer Cognition does this in Devin using a fine-tuned model.
LangGraph is a low-level orchestration framework, giving you full control over:
- Designing your agent as a set of nodes.
- Explicitly defining logic within each node.
- Passing a shared state object between nodes.
This makes it easy to compress context in different ways. For instance, you can:
- Use a message list as the agent state.
- Summarize it with built-in utilities.
We will b using the same RAG based tool calling agent we coded earlier and add summarization of its conversation history.
First, we need to extend our graph’s state to include a field for the final summary.
<span id="392e" data-selectable-paragraph=""><br><span>class</span> <span>State</span>(<span>MessagesState</span>):<br> <span>"""Extended state that includes a summary field for context compression."""</span><br> summary: <span>str</span></span>
Next, we’ll define a dedicated prompt for summarization and keep our RAG prompt from before.
<span id="3af2" data-selectable-paragraph=""><br>summarization_prompt = <span>"""Summarize the full chat history and all tool feedback to <br>give an overview of what the user asked about and what the agent did."""</span></span>
Now, we’ll create a summary_node.
- This node will be triggered at the end of the agent’s work to generate a concise summary of the entire interaction.
- The
llm_callandtool_noderemain unchanged.
<span id="90ff" data-selectable-paragraph=""><span>def</span> <span>summary_node</span>(<span>state: MessagesState</span>) -> <span>dict</span>:<br> <span>"""<br> Generate a summary of the conversation and tool interactions.<br><br> Args:<br> state: The current state of the graph, containing the message history.<br><br> Returns:<br> A dictionary with the key "summary" and the generated summary string<br> as the value, which updates the state.<br> """</span><br> <br> messages = [SystemMessage(content=summarization_prompt)] + state[<span>"messages"</span>]<br> <br> <br> result = llm.invoke(messages)<br> <br> <br> <span>return</span> {<span>"summary"</span>: result.content}</span>
Our conditional edge should_continue now needs to decide whether to call a tool or move forward to the new summary_node.
<span id="d8a8" data-selectable-paragraph=""><span>def</span> <span>should_continue</span>(<span>state: MessagesState</span>) -> <span>Literal</span>[<span>"Action"</span>, <span>"summary_node"</span>]:<br> <span>"""Determine next step based on whether LLM made tool calls."""</span><br> last_message = state[<span>"messages"</span>][-<span>1</span>]<br> <br> <br> <span>if</span> last_message.tool_calls:<br> <span>return</span> <span>"Action"</span><br> <br> <span>return</span> <span>"summary_node"</span></span>
Let’s build the graph with this new summarization step at the end.
<span id="c1a1" data-selectable-paragraph=""><br>agent_builder = StateGraph(State)<br><br><br>agent_builder.add_node(<span>"llm_call"</span>, llm_call)<br>agent_builder.add_node(<span>"Action"</span>, tool_node)<br>agent_builder.add_node(<span>"summary_node"</span>, summary_node)<br><br><br>agent_builder.add_edge(START, <span>"llm_call"</span>)<br>agent_builder.add_conditional_edges(<br> <span>"llm_call"</span>,<br> should_continue,<br> {<br> <span>"Action"</span>: <span>"Action"</span>,<br> <span>"summary_node"</span>: <span>"summary_node"</span>,<br> },<br>)<br>agent_builder.add_edge(<span>"Action"</span>, <span>"llm_call"</span>)<br>agent_builder.add_edge(<span>"summary_node"</span>, END)<br><br><br>agent = agent_builder.<span>compile</span>()<br><br><br>display(Image(agent.get_graph(xray=<span>True</span>).draw_mermaid_png()))</span>
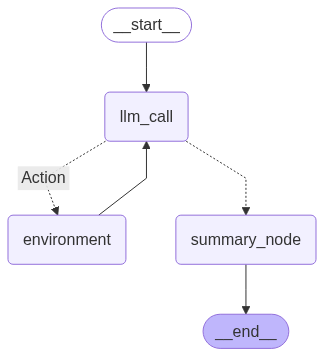
Our Created Agent (Created by )
Now, let’s run it with a query that will require fetching a lot of context.
<span id="6165" data-selectable-paragraph=""><span>from</span> rich.markdown <span>import</span> Markdown<br><br>query = <span>"Why does RL improve LLM reasoning according to the blogs?"</span><br>result = agent.invoke({<span>"messages"</span>: [(<span>"user"</span>, query)]})<br><br><br>format_message(result[<span>'messages'</span>][-<span>1</span>])<br><br><br>Markdown(result[<span>"summary"</span>])<br><br><br><br>The user asked about why reinforcement learning (RL) improves LLM re...</span>
Nice, but it uses 115k tokens! You can see the full trace here. This is a common challenge with agents that have token-heavy tool calls.
A more efficient approach is to compress the context before it enters the agent’s main scratchpad. Let’s update the RAG agent to summarize the tool call output on the fly.
First, a new prompt for this specific task:
<span id="8138" data-selectable-paragraph="">tool_summarization_prompt = <span>"""You will be provided a doc from a RAG system.<br>Summarize the docs, ensuring to retain all relevant / essential information.<br>Your goal is simply to reduce the size of the doc (tokens) to a more manageable size."""</span></span>
Next, we’ll modify our tool_node to include this summarization step.
<span id="4a16" data-selectable-paragraph=""><span>def</span> <span>tool_node_with_summarization</span>(<span>state: <span>dict</span></span>):<br> <span>"""Performs the tool call and then summarizes the output."""</span><br> result = []<br> <span>for</span> tool_call <span>in</span> state[<span>"messages"</span>][-<span>1</span>].tool_calls:<br> tool = tools_by_name[tool_call[<span>"name"</span>]]<br> observation = tool.invoke(tool_call[<span>"args"</span>])<br> <br> <br> summary_msg = llm.invoke([<br> SystemMessage(content=tool_summarization_prompt),<br> (<span>"user"</span>, <span>str</span>(observation))<br> ])<br> <br> result.append(ToolMessage(content=summary_msg.content, tool_call_id=tool_call[<span>"id"</span>]))<br> <span>return</span> {<span>"messages"</span>: result}</span>
Now, our should_continue edge can be simplified since we don’t need the final summary_node anymore.
<span id="cfde" data-selectable-paragraph=""><span>def</span> <span>should_continue</span>(<span>state: MessagesState</span>) -> <span>Literal</span>[<span>"Action"</span>, END]:<br> <span>"""Decide if we should continue the loop or stop."""</span><br> <span>if</span> state[<span>"messages"</span>][-<span>1</span>].tool_calls:<br> <span>return</span> <span>"Action"</span><br> <span>return</span> END</span>
Let’s build and compile this more efficient agent.
<span id="7c65" data-selectable-paragraph=""><br>agent_builder = StateGraph(MessagesState)<br><br><br>agent_builder.add_node(<span>"llm_call"</span>, llm_call)<br>agent_builder.add_node(<span>"Action"</span>, tool_node_with_summarization)<br><br><br>agent_builder.add_edge(START, <span>"llm_call"</span>)<br>agent_builder.add_conditional_edges(<br> <span>"llm_call"</span>,<br> should_continue,<br> {<br> <span>"Action"</span>: <span>"Action"</span>,<br> END: END,<br> },<br>)<br>agent_builder.add_edge(<span>"Action"</span>, <span>"llm_call"</span>)<br><br><br>agent = agent_builder.<span>compile</span>()<br><br><br>display(Image(agent.get_graph(xray=<span>True</span>).draw_mermaid_png()))</span>
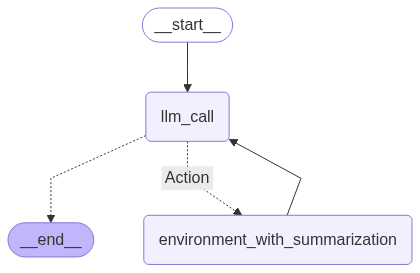
Our Updated Agent (Created by )
Let’s run the same query and see the difference.
<span id="0873" data-selectable-paragraph="">query = <span>"Why does RL improve LLM reasoning according to the blogs?"</span><br>result = agent.invoke({<span>"messages"</span>: [(<span>"user"</span>, query)]})<br>format_messages(result[<span>'messages'</span>])</span>
<span id="4c8e" data-selectable-paragraph="">┌────────────── user ───────────────┐<br>│ Why does RL improve LLM reasoning?│<br>│ According to the blogs? │<br>└───────────────────────────────────┘<br><br>┌────────────── 📝 AI ──────────────┐<br>│ Searching Lilian Weng’s blog for │<br>│ how RL improves LLM reasoning... │<br>│ │<br>│ 🔧 Tool Call: retrieve_blog_posts │<br>│ Args: { │<br>│ "query": "Reinforcement Learning │<br>│ for LLM reasoning" │<br>│ } │<br>└───────────────────────────────────┘<br><br>┌────────────── 🔧 Tool Output ─────┐<br>│ Lilian Weng explains RL helps LLM │<br>│ reasoning by training on rewards │<br>│ for each reasoning step (Process- │<br>│ based Reward Models). This guides │<br>│ the model to think step-by-step, │<br>│ improving coherence and logic. │<br>└───────────────────────────────────┘<br><br>┌────────────── 📝 AI ──────────────┐<br>│ RL improves LLM reasoning by │<br>│ rewarding stepwise thinking via │<br>│ PRMs, encouraging coherent, │<br>│ logical argumentation over final │<br>│ answers. It helps the model self- │<br>│ correct and explore better paths. │<br>└───────────────────────────────────┘</span>
This time, the agent only used 60k tokens See the trace here.
This simple change cut our token usage nearly in half, making the agent far more efficient and cost-effective.
You can learn more about:
- Heuristic Compression and Message Trimming managing token limits by trimming messages to prevent context overflow.
- SummarizationNode as Pre-Model Hook summarizing conversation history to control token usage in ReAct agents.
- LangMem Summarization strategies for long context management with message summarization and running summaries.
Isolating Context using Sub-Agents Architecture
A common way to isolate context is by splitting it across sub-agents. OpenAI Swarm library was designed for this “separation of concerns” where each agent manages a specific sub-task with its own tools, instructions, and context window.
Zoom image will be displayed
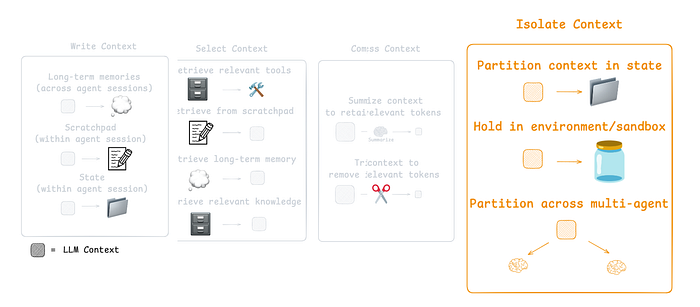
Fourth Component of CE (From LangChain docs)
Anthropic’s multi-agent researcher showed that multiple agents with isolated contexts outperformed a single agent by 90.2%, as each sub-agent focuses on a narrower sub-task.
Subagents operate in parallel with their own context windows, exploring different aspects of the question simultaneously.
However, multi-agent systems have challenges:
- Much higher token use (sometimes 15× more tokens than single-agent chat).
- Careful prompt engineering is required to plan sub-agent work.
- Coordinating sub-agents can be complex.
Zoom image will be displayed
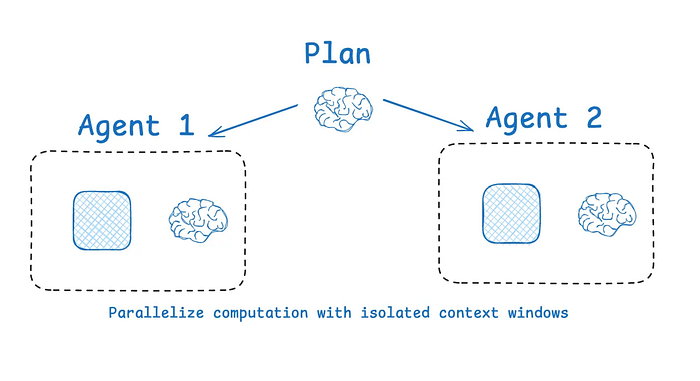
Multi Agent Parallelization (From LangChain docs)
LangGraph supports multi-agent setups. A common approach is the supervisor architecture, also used in Anthropic multi-agent researcher. The supervisor delegates tasks to sub-agents, each running in its own context window.
Let’s build a simple supervisor that manages two agents:
math_experthandles mathematical calculations.research_expertsearches and provides researched information.
The supervisor will decide which expert to call based on the query and coordinate their responses within the LangGraph workflow.
<span id="ce12" data-selectable-paragraph=""><span>from</span> langgraph.prebuilt <span>import</span> create_react_agent<br><span>from</span> langgraph_supervisor <span>import</span> create_supervisor<br><br><br><span>def</span> <span>add</span>(<span>a: <span>float</span>, b: <span>float</span></span>) -> <span>float</span>:<br> <span>"""Add two numbers."""</span><br> <span>return</span> a + b<br><br><span>def</span> <span>multiply</span>(<span>a: <span>float</span>, b: <span>float</span></span>) -> <span>float</span>:<br> <span>"""Multiply two numbers."""</span><br> <span>return</span> a * b<br><br><span>def</span> <span>web_search</span>(<span>query: <span>str</span></span>) -> <span>str</span>:<br> <span>"""Mock web search function that returns FAANG company headcounts."""</span><br> <span>return</span> (<br> <span>"Here are the headcounts for each of the FAANG companies in 2024:\n"</span><br> <span>"1. **Facebook (Meta)**: 67,317 employees.\n"</span><br> <span>"2. **Apple**: 164,000 employees.\n"</span><br> <span>"3. **Amazon**: 1,551,000 employees.\n"</span><br> <span>"4. **Netflix**: 14,000 employees.\n"</span><br> <span>"5. **Google (Alphabet)**: 181,269 employees."</span><br> )</span>
Now we can create our specialized agents and the supervisor to manage them.
<span id="cd47" data-selectable-paragraph=""><br>math_agent = create_react_agent(<br> model=llm,<br> tools=[add, multiply],<br> name=<span>"math_expert"</span>,<br> prompt=<span>"You are a math expert. Always use one tool at a time."</span><br>)<br><br>research_agent = create_react_agent(<br> model=llm,<br> tools=[web_search],<br> name=<span>"research_expert"</span>,<br> prompt=<span>"You are a world class researcher with access to web search. Do not do any math."</span><br>)<br><br><br>workflow = create_supervisor(<br> [research_agent, math_agent],<br> model=llm,<br> prompt=(<br> <span>"You are a team supervisor managing a research expert and a math expert. "</span><br> <span>"Delegate tasks to the appropriate agent to answer the user's query. "</span><br> <span>"For current events or facts, use research_agent. "</span><br> <span>"For math problems, use math_agent."</span><br> )<br>)<br><br><br>app = workflow.<span>compile</span>()</span>
Let’s execute the workflow and see how the supervisor delegates tasks.
<span id="2b10" data-selectable-paragraph=""><br>result = app.invoke({<br> <span>"messages"</span>: [<br> {<br> <span>"role"</span>: <span>"user"</span>,<br> <span>"content"</span>: <span>"what's the combined headcount of the FAANG companies in 2024?"</span><br> }<br> ]<br>})<br><br><br>format_messages(result[<span>'messages'</span>])</span>
<span id="80db" data-selectable-paragraph="">┌────────────── user ───────────────┐<br>│ Learn more about LangGraph Swarm │<br>│ and multi-agent systems. │<br>└───────────────────────────────────┘<br><br>┌────────────── 📝 AI ──────────────┐<br>│ Fetching details on LangGraph │<br>│ Swarm and related resources... │<br>└───────────────────────────────────┘<br><br>┌────────────── 🔧 Tool Output ─────┐<br>│ **LangGraph Swarm** │<br>│ Repo: │<br>│ https://github.com/langchain-ai/ │<br>│ langgraph-swarm-py │<br>│ │<br>│ • Python library for multi-agent │<br>│ AI with dynamic collaboration. │<br>│ • Agents hand off control based │<br>│ on specialization, keeping │<br>│ conversation context. │<br>│ • Supports custom handoffs, │<br>│ streaming, memory, and human- │<br>│ in-the-loop. │<br>│ • Install: │<br>│ `pip install langgraph-swarm` │<br>└───────────────────────────────────┘<br><br>┌────────────── 🔧 Tool Output ─────┐<br>│ **Videos on multi-agent systems** │<br>│ 1. https://youtu.be/4nZl32FwU-o │<br>│ 2. https://youtu.be/JeyDrn1dSUQ │<br>│ 3. https://youtu.be/B_0TNuYi56w │<br>└───────────────────────────────────┘<br><br>┌────────────── 📝 AI ──────────────┐<br>│ LangGraph Swarm makes it easy to │<br>│ build context-aware multi-agent │<br>│ systems. Check videos for deeper │<br>│ insights on multi-agent behavior. │<br>└───────────────────────────────────┘</span>
Here, the supervisor correctly isolates the context for each task sending the research query to the researcher and the math problem to the mathematician showing effective context isolation.
You can learn more about:
- LangGraph Swarm a Python library for building multi-agent systems with dynamic handoffs, memory, and human-in-the-loop support.
- Videos on multi-agent systems additional insights into building collaborative AI agents (video 2, video 3).
Isolation using Sandboxed Environments
HuggingFace’s deep researcher shows a cool way to isolate context. Most agents use tool calling APIs that return JSON arguments to run tools like search APIs and get results.
HuggingFace uses a CodeAgent that writes code to call tools. This code runs in a secure sandbox, and results from running the code are sent back to the LLM.
This keeps heavy data (like images or audio) outside the LLM’s token limit. HuggingFace explains:
[Code Agents allow for] better handling of state … Need to store this image/audio/other for later? Just save it as a variable in your state and use it later.
Using sandboxes with LangGraph is easy. The LangChain Sandbox runs untrusted Python code securely using Pyodide (Python compiled to WebAssembly). You can add this as a tool to any LangGraph agent.
Note: Deno is required. Install it here: https://docs.deno.com/runtime/getting_started/installation/
<span id="7656" data-selectable-paragraph=""><span>from</span> langchain_sandbox <span>import</span> PyodideSandboxTool<br><span>from</span> langgraph.prebuilt <span>import</span> create_react_agent<br><br><br>tool = PyodideSandboxTool(allow_net=<span>True</span>)<br><br><br>agent = create_react_agent(llm, tools=[tool])<br><br><br>result = <span>await</span> agent.ainvoke(<br> {<span>"messages"</span>: [{<span>"role"</span>: <span>"user"</span>, <span>"content"</span>: <span>"what's 5 + 7?"</span>}]},<br>)<br><br><br>format_messages(result[<span>'messages'</span>])</span>
<span id="8c89" data-selectable-paragraph="">┌────────────── user ───────────────┐<br>│ what's 5 + 7? │<br>└──────────────────────────────────┘<br><br>┌────────────── 📝 AI ──────────────┐<br>│ I can solve this by executing │<br>│ Python code in the sandbox. │<br>│ │<br>│ 🔧 Tool Call: pyodide_sandbox │<br>│ Args: { │<br>│ "code": "print(5 + 7)" │<br>│ } │<br>└──────────────────────────────────┘<br><br>┌────────────── 🔧 Tool Output ─────┐<br>│ 12 │<br>└──────────────────────────────────┘<br><br>┌────────────── 📝 AI ──────────────┐<br>│ The answer is 12. │<br>└──────────────────────────────────┘</span>
State Isolation in LangGraph
An agent’s runtime state object is another great way to isolate context, similar to sandboxing. You can design this state with a schema (like a Pydantic model) that has different fields for storing context.
For example, one field (like messages) is shown to the LLM each turn, while other fields keep information isolated until needed.
LangGraph is built around a state object, letting you create a custom state schema and access its fields throughout the agent’s workflow.
For instance, you can store tool call results in specific fields, keeping them hidden from the LLM until necessary. You’ve seen many examples of this in these notebooks.
Summarizing Everything
Let’s summarize, what we have done so far:
- We used LangGraph
StateGraphto create a “scratchpad” for short-term memory and anInMemoryStorefor long-term memory, allowing our agent to store and recall information. - We demonstrated how to selectively pull relevant information from the agent’s state and long-term memory. This included using Retrieval-Augmented Generation (
RAG) to find specific knowledge andlanggraph-bigtoolto select the right tool from many options. - To manage long conversations and token-heavy tool outputs, we implemented summarization.
- We showed how to compress
RAGresults on-the-fly to make the agent more efficient and reduce token usage. - We explored keeping contexts separate to avoid confusion by building a multi-agent system with a supervisor that delegates tasks to specialized sub-agents and by using sandboxed environments to run code.
All these techniques fall under “Contextual Engineering” a strategy to improve AI agents by carefully managing their working memory (context) to make them more efficient, accurate, and capable of handling complex, long-running tasks.